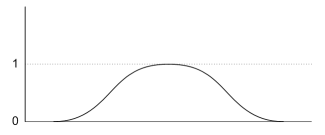
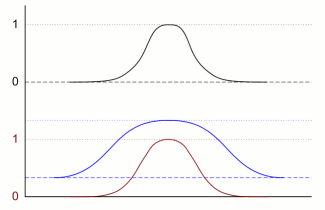
Combinaties van eigenschappenMenselijke eigenschappen zijn van de meer of minder soort, en niet van de ja-nee of zwart-wit soort. Dat betekent dat als je gaat kijken wie of hoeveel mensen een bepaalde eigenschap hebben, je altijd een min of meer continue verdeling vindt, die in een groot aantal van de "normale" of Gaussiaanse soort isNu is het zelden zo dat processen afhangen van één enkele eigenschap. Hier gaan we kijken naar de resultaten van diverse soorten combinaties van dit soort vaag begrensde eigenschappen. Als basisvorm van onze vaag-begrensde eigenschap kiezen we een verdeling die enigszins op de Gaussiaanse lijkt, zie onder - dat kan het aantal mensen zijn dat een bepaalde eigenschap heeft, bijvoorbeeld lengte - met horizontaal de lengte en verticaal het aantal mensen met die lengte - voor het gemak van de berekeningen hebben we de maximale hoogte van de grafiek 1 gemaakt (in wiskundige termen: genormeerd), waarbij 1 bijvoorbeeld voor 1000 mensen staat:
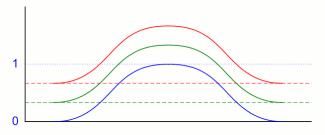
De combinatie van meerdere eigenschappen versimpelen we tot het geval dat de verdelingen ervan (ongeveer) hetzelfde uitzien - in onderstaande figuur hebben we er drie genomen, ieder met een eigen kleur. Omdat we ze in dezelfde grafiek hebben gezet, en toch niet over elkaar heen willen laten vallen, is de horizontale as voor iedere van de verdelingen wat verschoven, zodat ook de nulpunten telkens wat hoger liggen.
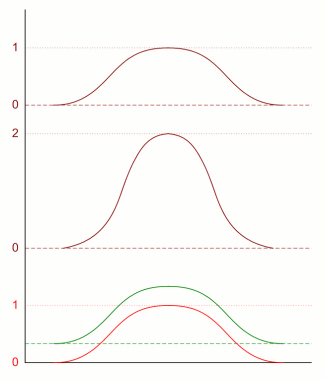
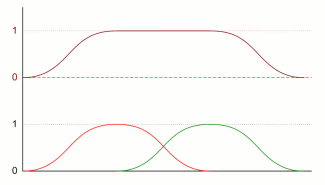
Nu gaan we deze verdelingen combineren. Daarvoor zijn twee principiëlere mogelijkheden: de eigenschappen die we combineren hebben niets met elkaar te maken, of de eigenschappen zijn afhankelijk van elkaar. Het eerste is bijvoorbeeld het geval bij lengte en muzikaliteit - er is nog nooit gebleken dat iemands muzikale talent van zijn lengte afhangt. Een voorbeeld van het tweede geval is lengte en gewicht - iemand van twee meter lang is meestal ook zwaarder dan iemand van anderhalve meter. Ook als je eigenschappen gaat combineren, kan je dat op een afhankelijke en een onafhankelijke manier doen. Als je iemand zoekt die of lang of muzikaal is, zeg je dat die twee onafhankelijk van elkaar zijn. Als je iemand zoekt die én lang én muzikaal is, maak je de twee eigenschappen afhankelijk van elkaar. Het combineren van onafhankelijke eigenschappen wordt wiskundig voorgesteld door het optellen van kansen en verdelingen: als de kans dat iemand erg muzikaal is 10 procent bedraagt, en dat hij erg lang is ook 10 procent, en je zoekt iemand die één van beide is, is je totale kans 20 procent. Als je daarentegen iemand zoekt die alletwee is, dan moet je met elkaar vermenigvuldigen, en de uiteindelijke kans is dan 1 procent (10 procent van 10 procent is een tiende van 10 procent). Wat betekent dat nu voor de verdelingen? We beginnen met het geval van onafhankelijke eigenschappen, en twee verdelingen, blauw en groen in de onderstaande figuur. Die tellen we bij elkaar op zodat je de bruine verdeling krijgt (dit doen voor een paar punten geeft al voldoende informatie om de trend te zien). Maar die bruine somgrafiek kan je niet vergelijken met de eerste twee, want die bruine is twee keer zo hoog. Je moet deze dus door twee delen - het hoeft geen verassing te zijn dat je dan precies dezelfde verdeling krijgt als de blauwe en de groene. Optellen verandert dus niets aan de vorm van verdelingen, als de oorspronkelijke tweede eenzelfde vorm hadden.
Het is duidelijk dat dit precies hetzelfde geldt als je er een derde verdeling bijneemt - dus dat laten we verder achterwege. Nu het geval van afhankelijke eigenschappen. Weer doen we dit met de eerder gebruikte blauwe en groene verdeling. Maar nu moet je vermenigvuldigen. De top van de grafiek blijft nu even hoog. Maar lage gedeelten worden extra laag - weer het geval van een tiende maal een tiende is een honderdste. De bruine grafiek ziet er duidelijk anders uit dan de originele. De bruine grafiek is een stuk smaller - het is een scherpere verdeling dan de rode of groene:
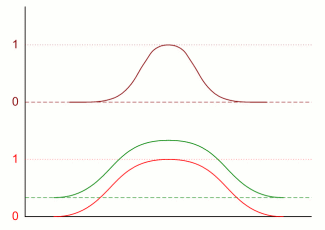
Oftewel: voor de combinatie van eigenschappen is het veel duidelijker wie wel of niet aan de combinatie voldoet dan voor de twee originele verdelingen. Ook geheel volgens ons praktijkvoorbeeld: als je de groep van muzikale én lange mensen zoekt, krijg je ook een selectere groep. Een trend die zich duidelijk voortzet als je een derde verdeling erbij neemt:
Vergeleken met de oorspronkelijke blauwe verdeling is het product van drie van die verdelingen, de zwarte, veel nauwer en veel beter gedefinieerd qua begrenzing. Overigens werkt dit alleen als je voortdurend dezelfde doelgroepen neemt. Als je verschillende groepen gaat combineren, gaat het anders - of mis, afhankelijk van je doelstellingen. Als je bijvoorbeeld gaat zoeken naar lange mensen onder Afrikanen en muzikale mensen onder Chinezen, krijg je als je optelt een veel bredere groep. Dan ziet de grafiek er zo uit, nemende het meer algemene geval dat de groepen deels samenvallen (en ook weer het makkelijke geval genomen):
Een apart voorbeeld van dit geval is als je een wat groter aantal verdelingen neemt, vijf of meer, die deels samenvallen - er is een wiskundige wet die zegt dat als die verdelingen er niet al te bijzonder uitzien (niet met abrupte overgangen, enzovoort), de resulterende verdeling een Gaussiaanse of normale verdeling is Het vermenigvuldigend combineren van min of meer losstaande verdelingen heeft natuurlijk het tegenovergestelde effect. Alleen in het overlappende gebied vindt je dan resultaten, en is er geen overlap, dan is het resultaat nul. De meeste werkelijke gevallen zijn natuurlijk weer tussenvormen en/of combinaties van de hier gegeven gevallen. Maar de laatste moeten voldoende zijn om ook voor de meer ingewikkelde gevallen goede benaderende oplossingen te kunnen vinden. Een interessante praktische toepassing van dit model is de omgekeerde redenatie: als je een praktisch geval hebt van een groep die gedefinieerd is door een combinatie van eigenschappen, is het (normaliter) niet mogelijk die groep te definiëren naar één van die eigenschappen. Iedere eigenschap afzonderlijk is redelijk breed verdeeld, en gaat over de grenzen van de groep heen. Terwijl de combinatie van eigenschappen een redelijk scherp bepaalde groep definieert. Dit proces ligt aan de basis van vele misverstanden van sociologen en leken over groepen. Een ander punt, voor toepassing bij verdere uitwerking, is dat de dynamiek van dit soort groepen afhankelijk is van de samenhang tussen de definiërende eigenschappen. Als die eigenschappen volledig los staan, kan je de dynamiek van de groep alleen bepalen door die van ieder van de eigenschappen apart te bepalen. Zijn twee eigenschappen volledig gekoppeld, hoef je dat maar voor één van de twee te doen. Naar Evolutie
|